RAG As A Service
Qu’est-ce que la génération augmentée par récupération (RAG), et pourquoi est-elle importante pour les grands modèles de langage (LLM) ?
Les grands modèles de langage (LLM) sont devenus la colonne vertébrale des applications d’IA, des assistants virtuels aux outils d’analyse de données complexes. Cependant, malgré leurs capacités impressionnantes, ces modèles ont des limites, notamment lorsqu’il s’agit de fournir des informations à jour et exactes. C’est là que la génération augmentée par récupération (RAG) intervient, offrant une amélioration puissante aux LLM.
Le RAG améliore la pertinence et la précision des informations générées mais aussi la traçabilité de l’information et contribue notamment à réduire le risque d’hallucinations (réponses absurdes) par rapport à la simple utilisation d’un modèle d’IA générative.
Cette solution est accessible à toutes les entreprises, quelles que soient leurs tailles et secteur d’activité. En effet, elle ne nécessite pas de compétences en IA ni même en informatique en interne pour être adoptée, et les données utilisées pour la mettre en place peuvent aussi bien être des e-mails, documents textuels et PDF du quotidien que des bases de données juridiques ou techniques d’une grande complexité.
Qu’est-ce que la génération augmentée par récupération (RAG) ?
La génération augmentée par récupération (RAG) est une méthode avancée qui améliore les performances des grands modèles de langage (LLM) en intégrant des sources de connaissance externes dans leur processus de génération de réponses. Les LLM, entraînés sur de vastes ensembles de données et dotés de milliards de paramètres, excellent dans diverses tâches comme répondre à des questions, traduire des langues et compléter des phrases. Cependant, le RAG va plus loin en s’appuyant sur des bases de connaissances fiables et spécifiques à un domaine, ce qui améliore la pertinence, la précision et l’utilité des réponses générées sans réentraîner le modèle. Cette approche économique et efficace en fait une solution idéale pour les organisations qui cherchent à optimiser leurs systèmes d’IA.
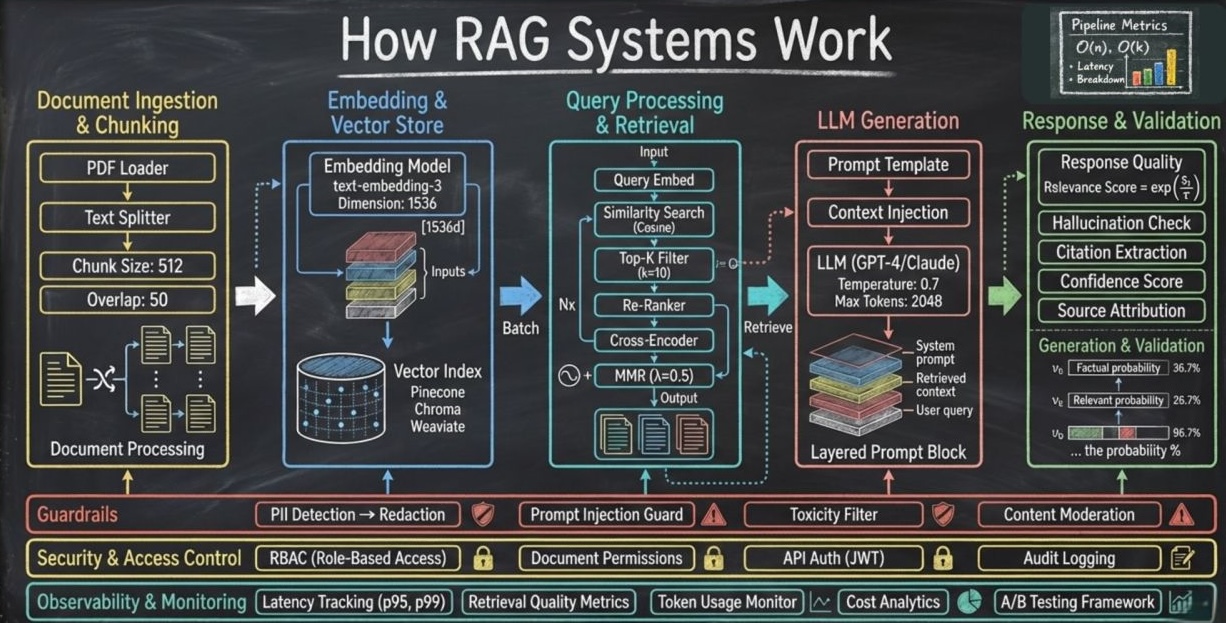
un RAG qui marche
La plupart des démonstrations de Retrieval-Augmented Generation (AI RAG) impressionnent parce qu’elles connectent un grand modèle de langage à un petit ensemble de documents soigneusement sélectionnés, produisant des réponses fluides et convaincantes. Pourtant, ces prototypes masquent des difficultés majeures dès que l’on quitte l’environnement contrôlé de la démo. Dans un contexte d’entreprise, avec des volumes massifs de documents hétérogènes, des mises à jour fréquentes et des usages multiples, la qualité des résultats diminue, la latence augmente et la confiance des utilisateurs s’érode. Le véritable problème ne réside pas dans la performance des modèles, mais dans une infrastructure de données incapable de soutenir la complexité opérationnelle.
L’échec de nombreux systèmes RAG en production tient souvent à une ingestion des données pensée comme un événement ponctuel plutôt que comme un processus continu. Lorsque la base de connaissances évolue rapidement, un système alimenté par des données statiques finit par fournir des réponses obsolètes, parfois techniquement exactes mais inadaptées à la réalité du moment. À grande échelle, ces imprécisions deviennent systémiques, la pertinence perçue diminue et les questions de sécurité, notamment la gestion fine des droits d’accès, se transforment en freins majeurs à l’adoption.
Le RAG ne peut pas être considéré comme une simple fonctionnalité à ajouter à une application existante ; il doit être conçu comme une véritable infrastructure. Une telle approche implique de gérer la montée en charge, la diversité des formats, la gouvernance des données et les contraintes réglementaires. La fiabilité d’un système RAG en production dépend autant de la qualité des réponses générées que de la capacité à garantir la traçabilité des sources, le respect des autorisations et une supervision continue des performances.
Construire un RAG robuste suppose donc de repenser en profondeur le traitement des données : mettre en place une ingestion continue, assurer un prétraitement adapté aux différents formats (y compris les documents complexes), appliquer des contrôles d’accès dynamiques au moment des requêtes et intégrer des mécanismes de re-classement pour améliorer la précision. Lorsqu’il est conçu comme une infrastructure évolutive plutôt que comme un simple ajout technologique, le RAG peut offrir des réponses fiables, sécurisées et durables, même dans des environnements en constante transformation.
Utilisez Verbatim AI et deployer votre RAG sans infrastructure
Nous agissons comme un RAG As A Service, sans aucune infrastructure. Essayez notre service et obtenez votre propre RAG gratuitement pendant 90 jours.
Questions Fréquentes
Trouvez des réponses aux questions fréquemment posées concernant notre service et notre technologie
Prêt à déployer votre propre Agent IA ?
Prenons quelques minutes pour faire connaissances et discuter de vos projets et de vos besoins.